Building a virtual machine image for one target hypervisor probably
doesn’t cut it anymore. If your organization is like most today, you
run VMware in production, and you’re investigating AWS or OpenStack
for burstability or a full blown migration, and your developers all
run VirtualBox on their laptops. Except for Marvin. Marvin runs KVM
because he’s a contributor to the project.
We can define cross-hypervisor machine definitions with
Packer.
We can run Packer on a variety of machines to provide full hypervisor
coverage with Jenkins.
Packer and Jenkins make a great team. They’re like peanut butter and
chocolate. Or coffee and chocolate. Or pastry and chocolate.
/me grabs a chocolate bar from his drawer and gets back on track.
Many organizations use a single Jenkins server to run continuous
integration builds, but Jenkins supports any number of slave nodes to
distribute load. Further, we can assign labels to those nodes that
define capabilities or other characteristics (host OS, installed
software, special hardware architecture, etc).
Jobs can be pinned to nodes with specific labels, and the NodeLabel
Parameter
Plugin
lets us use node labels as a parameter when building a job.
I give each of my build nodes a label of packer-${builder-name}, then
I can build any machine in my Packer Open Source
Appliances
repository on all of my available local hypervisors and cloud
accounts. My personal list includes qemu, docker, virtualbox-iso, and
openstack (with Rackspace).
I’m pretty excited about this, and I’ll share more details and
possible next steps in a future post. Until then, you can snag
the job definition from my repository.
Kallithea is a new source code
management system based on the GPL origins of RhodeCode. The project
needs a continuous integration service running in the open to
sufficiently test incoming patches across a matrix of configuration
variables. I’ve started looking into adding SSH authentication
capabilities, so solid automated testing platform is personally interesting.
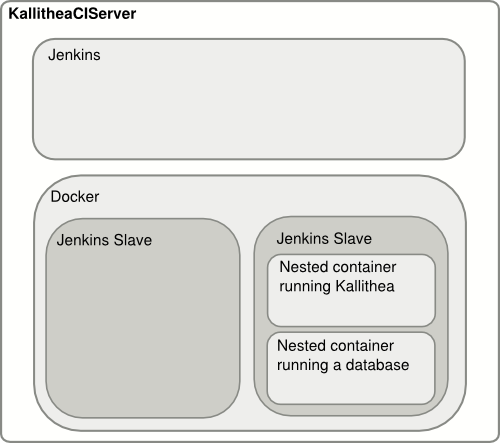
I am building a Jenkins server for this purpose. The server build
process is automated with Packer and
Puppet so that we can easily host the
system in a large variety of environments.
We can build rich single use test environments that launch quickly
The system can grow as our testing needs grow
At the least I imagine test jobs to run the following:
Unit tests
Integration tests with various infrastructure components (for instance: sqlite, MySQL, PostgreSQL)
Application upgrade tests
I’m happy to pay for the hosting of the CI service, but the open and
automated deployment definitions will allow anyone to build and run
their own system as well.
The first scraps of configuration are in the following two repositories:
Please let me know if you have any thoughts, questions, or concerns.
In addition to the mailing list, you can find me in the #kallithea IRC
channel as timfreund.
I’m evaluating OpenStack commercial
partners, and I’m interested in their ability to blend with our
current infrastructure. One vendor touted their automatic
provisioning and configuration management system, and I wondered if it
was just a re-brand of something like Puppet or Chef under the
covers. Puppet would be fantastic since we’re invested in that
technology already.
Google pointed me to a clarifying article:
… [PRODUCT] doesn’t rely on third-party products such as Puppet or
Chef to handle deployments. He claimed there was risk involved with using
such tools, especially with Puppet’s ties to VMWare, and suggested the
learning curve was higher using them than with his company’s package.
Risk happens. We dance with risk all day every day. With no more
specific information regarding the risks inherent in using an existing
provisioning and configuration management system, I must assume those
same risks are present using their home grown system. Nobody from
Puppet Labs will stop by the home office of this vendor and demand
exclusive use of VMWare hypervisors. The vendor is still free to
write their own Puppet modules for managing their OpenStack
implementations. The vendor is free to ignore Puppet all together
while still choosing a completely competent and capable configuration
management tool already in use by the community.
Concerning the learning curve problem, there’s only one explanation
that makes sense to me. I think he left out some words. I think he
meant something like “… the learning curve [for him and his PRODUCT
team] was higher using them than with his company’s package.” That
makes much more sense to me. It’s a tale as old as software
development. I’ve seen it in my own lifetime more than I care to
remember. It’s called NIH Syndrome, and it goes a little something
like this: “we don’t have time to learn [INDUSTRYSTANDARDPACKAGE],
so we’re going to write our own instead.”
Because ignoring thousands of person hours worked by experts in the field
of that tiny portion of the domain will surely pay off in the long run
when your small team of generalists attacks the same problem for two weeks.
I’ve also heard trust arguments against existing components. “We
didn’t write it ourselves, so how can we trust it?” Right. A package
in use all over the world is obviously untrustworthy. That’s why I
write most of my software on a custom home built computer that I
soldered together myself. We’re going to need to make a bulk
transistor order from Radio Shack so I can build enough equipment to
run at scale. It’s the only way to be certain.
KITT captured my imagination when
I was four years old. If you weren’t a child of the 80’s, you may not
know the depths of KITT’s awesomeness. Gaze carefully at his
feature list and try to
control the swell of emotions that stir deep within you. A “Molecular
Bonded Shell”, a “Third Stage Aquatic Synthesizer”, “Passive Laser
Restraint System”, a built-in ATM, and an artificially intelligent
personality voiced by
Mr. Feeny. I wanted a
Firebird or Trans Am for years after seeing KITT in action.
Around the same time that KITT was on television, my dad was shopping
for a new vehicle to replace his incredibly crappy Buick Skylark.
Although he eventually purchased a totally plain and perfectly
suitable Dodge Ram pickup truck, he considered a couple of different
options before signing on any dotted lines. I’m fairly certain he
test drove a Dodge Daytona, and it mesmerized me. It had a bright,
digital dashboard reminiscent of KITT’s. The steering apparatus was a
totally boring wheel, but I was willing to overlook it. Not every car
can have a yoke.
Decades later I rented a car with a digital dashboard. Once the
novelty wore off, I was disappointed with the utility of it all. The
two digit speed display required reading. I couldn’t keep tabs on my
speed with my peripheral vision quite like I could in cars with
analog dials.
An analog gauge, whether physically analog or digitally rendered, provides
the moment in time value along with the context of expected and potential
ranges. For instance, the tachometer below shows a potential range
of 0 through 16 thousand RPM, but the area between 14K and 16K are clearly
marked to indicate potential trouble from running within that range:
Sidney Dekker talks about this briefly in chapter 14 of The Field Guide to Understanding Human Error. He claims that numeric digital readouts
“can hide interesting changes and events, or system anomalies.”
Why is it, then, that I have produced so many monitoring scripts that
produce little more than a two, or three, or four digit number as
output? The raw numbers are necessary but not sufficient for use in a
production support situation. The numbers must feed into a system
that will graphically provide context over time.
There’s a http monitor in F5’s BIGIP Local Traffic Managers.
Common opinion around the office said that any request returning
200 OK was successful in the eyes of the monitor. We found out
this isn’t the case today.
We deployed a blank index.html file at the root of the web server
since our application runs under a different context, and the health
monitor started to fail. Once we put some content in the file (the
text “Nothing to see here” in our case), everything turned green again.
This information is probably in the docs. I’m publishing it here
mainly for the sake of my own memory.
Let’s talk about installing Veewee to build virtual machines on
multiple platforms from templates with little to no ruby background.
Ruby professionals will probably do just fine with the install
instructions
provided by the project. Stick around if you’re a system
administrator, operations engineer, or non-ruby developer interested
in installing veewee.
After installing required operating system packages we come to the
first fork in the road. Two options with a silent third option
exist for managing our Ruby environment:
No environment management (preferred by no one sane)
Number three is an option in the technical sense only. Don’t think
it’s a wise idea to stink up the system Ruby installation with
custom gems. You’re entering a world of pain.
RVM felt a little weird to me, but I chalked that up to being a Ruby
rube. Joe told me that he dropped RVM years ago for rbenv and hasn’t
looked back. Those two factors pushed me to switch to rbenv, but your
mileage may vary. For the python folks in the room, you can equate
(RVM || rbenv) + Bundler to virtualenv + pip.
I followed the rest of the
installation,
command
options,
and
basics
pages. Everything worked, and I created several virtual machines using
the KVM plugin, but it didn’t quite feel right. I didn’t see anywhere in
the docs an explanation of how to separate my work from their work.
Templates and definitions lived inside of the veewee source directory,
and “bundle exec veewee” only worked within that directory.
Aside from the ugliness of polluting a directory full of upstream
source with my own stuff that I never intended to contribute back, I
really wanted a nice way to manage separate repositories of templates
and definitions for my personal use and work use.
I saw reference to Veeweefiles in the docs, but not much information
on how to use them to customize runtime configuration. Digging in to
the code, environment.rb specifically, there was a reference to a
VEEWEE_DIR environment variable. Setting that allowed me to run
bundle exec veewee from the veewee source directory, but use
templates, definitions, and isos in a separate directory. Excited
about this new development, I shared the news with some folks in IRC.
Joe again stepped in to let me know that I was just barely catching
up to the crowd, and not even in a very ideal way.
“make a gemfile that includes veewee, run bundle it, then the above
command [works in your personal directory for templates and definitions]”
The djsd binary wasn’t installed with the executable bit set when I
installed it from the
dotjs-ubuntu
repository. I’m running Ubuntu 12.04 on my desktop. Before
submitting a drive by pull request I tested 13.04, and it worked fine.
At this point I assumed it was either a version difference or
something wonky in my environment.
Testing on a clean 12.04 virtual machine pointed directly at my
environment. What was the difference? The machines that worked were
using the system provided ruby interpreter. The machine that didn’t
was using an RVM supplied ruby interpreter. I’m sure there’s more to
it than that, but as an infrequent ruby coder that’s all I needed to
know before deleting my dotjs-ubuntu fork and calling off the hounds.
And if you aren’t using dotjs, well, you should. It’s awesome. You
can inject javascript on a site by site basis. For instance, here’s
what keeps me from spending stupid amounts of time browsing imgur:
$('.post a').css('visibility','hidden'); $('div.jcarousel ul li a').css('visibility','hidden');
JavaScript
That file lives at ~/.js/imgur.com.js, and it removes links to
other images on any page served by the site.
It’s a compromise: In the past I’d block the site in my hosts file,
but friends would send me links to images. I’d oblige by removing the
host entry to view the link then regret that decision later. Will
power is a finite resource, and I can’t click on links that aren’t visible.
Gather around kids, and listen to a story about a user looking for
help. Years ago there was a bug report submitted to the MPlayer
project reporting a crash. The user gave a large amount of data to
increase the chances of finding a fix. He gave so much data, in fact,
that his bug report garnered 15 minutes of Internet fame because of
some explicit detail. A Shark’s
Tale was on his play list, and
if that wasn’t embarrassing enough, he also had some extremely NSFW
material right next to it.
MPlayer’s bugzilla installation migrated to a new host years ago, and
I suspect they consciously chose to remove or hide the blush-worthy
bug. I also suspect that once the childish giggling died down that
guy got his bug fixed. Why? Because he provided detail for
examination by the developers.
What happens when a bug or support request arrives without enough detail?
I received a vague bug report this afternoon that didn’t contain
enough detail to recreate. Over the course of 20 minutes we extracted
enough information to solve the problem, but this was only after the
ambiguous bug spent the better part of a month in queue with everyone
raising an eyebrow, shrugging, and moving on to more fertile debugging pastures.
There’s hardly a thing as too much detail when submitting support
requests. Providing sufficient detail sends two signals:
You’ve put forth effort to fix things yourself, and, short of that,
collect data for the people that will fix things.
You value the time of others. The experts assisting you will know
which bits to ignore, but they can’t even get started if they don’t
get enough info in the first place.
And if you insist on seeing the forum threads reporting on the crazy
MPlayer bug report, just search for: mplayer bug report Sharks Tale.
But not at work. Or really ever. It’s silly Internet shenannigans.
The PassLib New Application Quickstart
Guide
reveals more information about password hashing than I knew at all
before reading the page. Hashing and cryptography are two different
things, but, as with crypto code, it’s best to leave password hashing
to someone who knows the subject front and back.
I spent some time reading through the hashing routine in an old
application to build an administrative password reset tool. We salt,
and we use a decent hashing algorithm, but the code isn’t nearly as
sophisticated as what we’d get with the default context provided by PassLib.
Here’s a preferential order of password storage algorithms:
-2. Passwords stored in plain text -1. Passwords reversibly encrypted 0. Passwords naively hashed with a weak algorithm 1. Passwords salted and hashed 2. Passwords salted and hashed with a carefully chosen algorithm and procedure
Users will reuse passwords in your application. Storing weakly
hashed or encrypted passwords opens your users’ email, social media,
shopping, and banking accounts to fraud and abuse should your
application ever be compromised. Users hate that. Don’t let
your users hate you over something so easy to do well with the
help of open source libraries.
Today we configure a DD-WRT router to allow servers on a KVM
virtual routed network access to the local network and the internet.
If you’ve found entry #3 in this libvirt networking FAQ and you’re now
searching for the solution, you may be close.
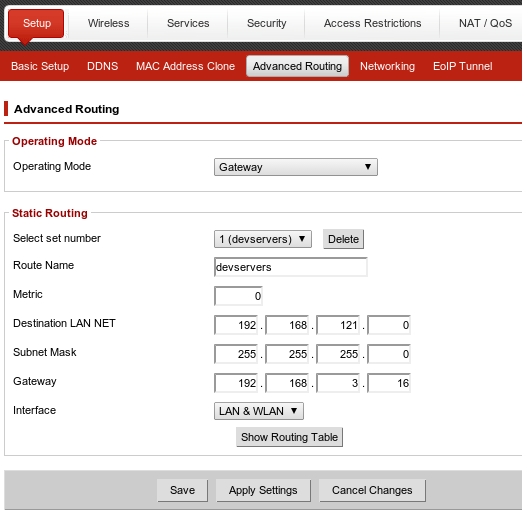
First, we need to let the DD-WRT router know about the new network.
This is under Setup -> Advanced Routing on my Buffalo device, and
hopefully not far from there on your device.
Under “Static Routing” fill in appropriate values:
Route Name: your choice
Destination LANNET: the network address of your KVM virtual routed network.
Subnet Mask: Probably 255.255.255.0, but you’ll know better if it isn’t.
Gateway: The LAN address of the host that runs your KVM virtual routed network.
Interface: LAN&WLAN
Save and apply those settings, then try to ping the router from a
virtual machine on the virtual network and vice versa. Assuming both
pings work, we’re ready for phase two.
Anything on the LAN can now talk to anything else on the LAN, but the
virtual machines on the routed virtual network can’t talk to the
Internet yet. Any attempts will time out. This assumes your DD-WRT
router does NAT (Network Address Translation) for hosts on your LAN
when they access the internet, but you’ll know better if it doesn’t and
you probably wouldn’t be reading this right now.
The DD-WRT router knows to apply NAT to any traffic heading to the
internet originating from the local network configured in the “Setup”
-> “Basic Setup” -> “Network Setup” -> “Router IP” configuration area.
It does not apply NAT rules to any traffic originating on any other
network that happens to come its way.
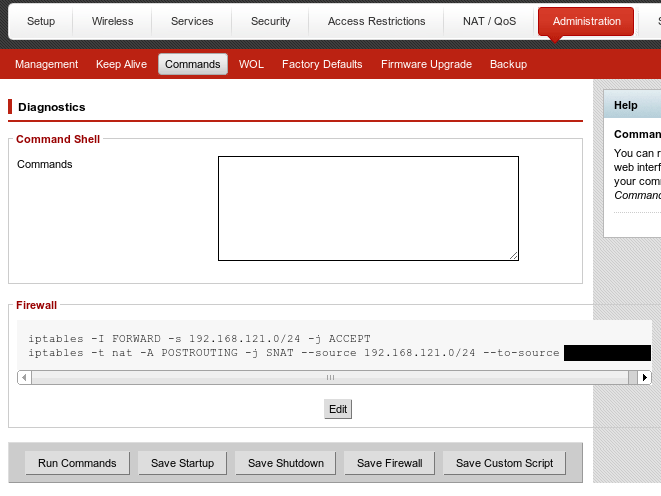
That configuration happens in the “Administration” -> “Commands” area
of the administrative interface.
Click “Save Firewall” so the commands will run after each reboot, and
click “Run Commands” to execute the commands immediately. Once
complete, log in to one of your virtual machines and try to access any
site on the Internet. With any luck it now works. I’m perhaps a bit
lucky because I have a static IP address at home. I’m not sure how to
dynamically update that command to include the correct WANIP if you
use DHCP. I’ll offer up the following bit of shell scripting in case
it helps:
That dumps the routing table and extracts the default gateway for the
device. I’ll update this post if you can tell me a better way to get
that information.
(I just upgraded to 1.2.1, and I’m updating this doc accordingly)
Getting Apt-Cacher NG
installed with such little fanfare and such huge payoff put me in a
mood to cache more stuff.
We have an embarrassment of riches when it comes to caching PyPi packages
for a network of hosts. I found four contenders, and I didn’t look very hard.
The long activity history as well as the well written
documentation pushed me toward devpi.
It’s working so well that I feel no need to try the alternatives. It
installed in a virtualenv, and it behaves under upstart management.
# /etc/init/devpi.conf description "devpi"
setuid www-data setgid www-data
start on runlevel [2345] stop on runlevel [!2345] respawn
Disposable systems eliminate the variability and cruft that
accumulates over time. I look at some of the long lived dev and test
systems at work, and I cringe because a parade of developers has each
left their mark, and each special touch pushes those environments
further from production. I did it too, and we’re making things
better. Please don’t throw stones at my glass house.
CERN’s Tim Bell put it best when he compared long lived systems to pets
and disposable systems to cattle.
To make the disposable cattle model work, the orchestration system
must create and configure new systems in less time than it’d take to
retrofit a long lived pet machine. We won’t wait for new machines
just like we won’t wait for a slow unit test suite to run.
Apt-Cacher NG sits on the
local network and silently proxies and caches requests for Debian or
Ubuntu packages. The first installation of a package will go as quickly
as the Apt-Cacher’s connection to the upstream mirror, but subsequent
installations will run as quickly as the local network link. That’s
typically an order of magnitude or three in throughput.
Apt-Cacher NG is included in the default repositories for Ubuntu, and
installation is ridiculously easy. Once it is running, client
configuration is also ridiculously easy.
People who use preseed.cfg files (VeeWee, Foreman, or other automatic system
provisioning tools) should add or update the following line:
I did not pick Apt-Cacher NG over Apt-Cacher just because of the NG
designation. My first cache server attempt was Apt-Cacher as laid
out in the Ubuntu community
docs. It
installed easily, but it locked up hard when I tried to run apt-get
update against it.
I knew of but chose to ignore apt-mirror
because I use a very tiny subset of packages. Apt-mirror may be the way
to go if you’re supporting a wide range of systems and use cases.
It’s not perfect. It’s not a gospel. But it is pretty solid. Spend
the 10 to 20 minutes it will take you to read if deploying code
induces cold sweats.
Maybe once you’re done you can convince me that sending all logs to
stdout is the right thing to do as outlined in Factor
11. It advocates offloading log management
to an external process, and I don’t understand the benefit of that
over a mature logging framework built in to the application. I’m not
convinced, but I’m not unconvincable.
But every increase in sensitivity resulted in a large increase in the
expected number of false alarms. The designers did not understand
that in the monitoring of a test ban treaty, a high false-alarm rate
would be far more troublesome politically than a low detection rate.
… This is the paradox: too much verification may be as bad as too little.
Scientists and engineers worked on the technical implementation of a
nuclear test ban treaty with little regard for politics. These
professionals made up the top echelon of thought across their areas of
expertise, and they aimed for accuracy. No expense would be spared in
the quest for accurate detection of nuclear blasts regardless of their
size or location.
The rapid escalation inherent in nuclear conflict raised the cost of
inaccurate blast detection to such a level that missing a blast would
actually be preferable to accidentally classifying an earthquake or
other natural event as a blast. Exponentially so if the detection
system was ever wired in to a rapid response system, automated or not.
How rapid is rapid escalation? Most of the people reading this grew
up in the United States. Think back to grade school. Do you remember
the nuclear shelter area in your school if there was one at all? At
Queen of the Holy Rosary grade school it was the 400 square foot art
classroom. It was in the basement, and there were no windows, but
there was also no seal on the door, and no ventilation system, and no
stockpile of food or water. It was a tight fit for art class, and
there were only 21 kids in my grade. That fallout shelter checked a
box on a long and meticulously designed civil defense form, but it
sure as hell wasn’t going to provide any shelter from fallout for the
160 kids and 20 staff members in the building if the need arose.
That ridiculously undersized and understocked basement room wasn’t an
oversight or a corrupt attempt to save money. It was a conscious
decision driven by the strategies and attitudes of the Cold War.
Shelters are perceived to be futile because the assured destruction
strategy demands that they be ineffective. [Capable] Shelters are
perceived to be threatening because they suggest an intention to make
the operation of assured destruction unilateral.
“A strange game. The only winning move is not to play.”
Monitoring enterprise IT beats us all down at times, but no one dies
in the course of our experimentation. Tweet about how much
#monitoringsucks all you want. Get it out of your system and then
recall that we have the power and time to make things better without
killing most of the human population.
Small changes made frequently makes monitoring suck less, so make
some changes. Just don’t kill anyone.
I’ve been working under an assumption: WSGI abstracts away all of the
details of serving up a python web application so well that WSGI web
server implementations are totally interchangeable without thought or worry.
WSGI is awesome, but not quite that awesome. Abstractions are leaky,
it’s a law.
IronBlogger development
has picked back up thanks to Julython, and
the deployment went as planned until I restarted the process. It got
stuck in an infinite loop of restarting itself, with exceptions thrown
in the database initialization code.
I used the pip freeze command to dump lists of installed software in
each host, and gunicorn was the only additional bit of code in the
production environment. And, sensibly, the only difference outside of
turning off live debugging was the gunicorn configuration:
I haven’t figured out exactly what the problem is, but I’m getting close. This
is primarily a public service announcement: test your code with the same server
software that it’ll run on in production. Abstractions are leaky, and it
may work for a while, but one day it won’t.
FPM changed the way I think
about packaging. I wrote so many lines of custom deployment code just
to skip packaging our in-house application in the past, and it was
completely justifiable given my previous experience with packaging tools
I mentioned last time
that we’re living in the future. Things have changed for the better.
We now use Puppet for provisioning and
configuration management, and that extends to our in-house
applications running on those servers. We also have internal package
repositories. Packaging pain kept us from fully using this
infrastructure for our in-house applications, but FPM changes that.
Say we have a custom application to package. This isn’t an official
release, it’s just a build triggered by the latest commit, and we have
it laid out on disk just like it should be deployed. Easy:
Note that we’re creating RPM packages above. Also note that the -t
argument defines the OUTPUT_TYPE or target. Swap in deb for rpm
to get a Debian themed party started. Solaris packages are an option,
too. That’s right, some people still deploy more than just Oracle
products on Solaris machines.
Libvirt + QEMU + KVM allows easy virtualization
on Linux. Virtual machines are placed on a virtual network that comes
complete with a DHCP server and DNS forwarder. There’s no reason to
give up these default conveniences until your work involves building
and configuring DNS and DHCP servers. Running two DHCP servers on the
same virtual network is a recipe for frustration.
The configuration files for libvirt are stored in /etc/libvirt by
default, but pretend like they aren’t even there. Read any of the files
and you’ll find a warning:
<!-- WARNING: THISISANAUTO-GENERATEDFILE. CHANGESTOITARELIKELYTOBE OVERWRITTENANDLOST. Changes to this xml configuration should be made using: virsh net-edit devservers or other application using the libvirt API. -->
XML
They aren’t kidding. Don’t change these files. There’s one other trick:
Running the net-edit command alone won’t really do anything either if the network
is already running. The following operations will do the trick:
Rumor has it that later versions of the virt-managerGUI support
these operations, but this info will come in handy if you’re still on
a LTS system.
Reconnect any hosts that were on the virtual network, because they
aren’t anymore. Configure your own DHCP server or configure all hosts
with static interfaces as well. Remember that you’re on your own for
DNS resolution in addition to DHCP at this point. An easy solution is
to set domain-name-servers in your dhcpd.conf file to your router
or access point.
Now that we’ve wrapped up our business here, I’d like to take a minute
to tell you how happy all this stuff makes me. I’m running a small
colony of machines on my middle of the line desktop computer, and I
can practice the exact same work that happens in real data centers.
Back when I was a newbie every machine was a real, physical machine,
and PXE booting required careful hardware selection.
We’re living in the future. We just need the Hoverboard design team to
catch up.
I’m a bash user, so I can set $PS1 to contain a variety of useful
information, and my prompt will vary depending on where I’m at. We
have enough servers and services at $DAYJOB that the following makes a
lot of sense:
People tell me that showing the time is silly. I like it because
there are times when I run a long running process and walk away while
it churns. It’s often helpful to know how long something took, and
having timestamps on each line let me know.
It’s helpful to me personally as well. There are many times when I’m
drawn away from scheduled work into an urgent support situation, and
I’ll leave my scheduled work as-is and work the urgent situation in a new
terminal tab or window. That’s exactly what happened today, and I was
a little shocked at the story the timestamps had to tell:
Over four hours. I’ll admit that wasn’t all urgent support. I ate
lunch and checked email, too. It took a look at my important task
list to jog my memory back to the work I was doing at 10:28. “Oh,
right, that’s what I really need to finish today.”
Working for 8 solid hours is an illusion. It’s not going to happen.
Unless work happens in a cabin off the grid away from civilization,
interruptions will wreck your day. Almost every day. More important
than blocking off 8 solid hours is to put in place systems to
continually nudge ourselves toward the important tasks once the storms
of unavoidable urgent work have passed.
My favorites include:
Pomodoro timers (I wrote one, it’s big, and color coded)
Ignaz Semmelweis, the doctor that recommended hand washing between
patients in 1847, died in an asylum. His fellow doctors were appalled
that anyone would think they were dirty. They were educated
gentlemen. How rude of him to imply that they could contribute to
ailments and disease. They were the cure, not the cause!
We’re 166 years out from Dr. Semmelweis’s revolutionary research, and
we’re all better off for it. Every desk in my office has a bottle of
hand santizer on it. It’s in grocery stores near the dirty, filthy
carts. Moms carry it in purses. Yet just 6 months ago the following
was published:
“There will be a day when it will be so automatic for health care
workers to clean their hands,” Pittet said. “It will be a lot easier
at that time for patients, in case health care workers forgot, to
remind them.”
A third of doctors surveyed did not want patients reminding them to
wash up. If they were so smart they wouldn’t be sick.
Good thing that smug arrogance is an isolated incident limited to
personal cleanliness. Oh, right, cholera:
In 1854 London physician Dr John Snow discovered that [cholera] was
transmitted by drinking water contaminated by sewage after an epidemic
centered in Soho, but this idea was not widely accepted.
That’s from a Wikipedia article named Great
Stink. The name alone
warrants a quick skim, and you’ll also read about more doctors
ignoring research.
For instance, Filippo
Pacini discovered the
bacteria that causes cholera in the same year that Dr. Snow theorized
that transmission was via sewage, but nobody cared. Physicians knew
beyond doubt that cholera wasn’t caused by bacteria, but instead by
miasma. That’s bad air for those of us living with bacterial
awareness in 2013.
The same bacteria was rediscovered 30 years later by Robert Koch. He
also isolated the bacteria behind tuberculosis. I suspect other
physicians only took him seriously because he looked like a man that
you shouldn’t screw with.
At least now we’re more data driven. With the systematic cost conscious
approaches pioneered by modern health management organization, surely now
data and procedures rule.
Let’s talk central lines. A central venous catheter as it is called
in terms more complex than I commonly use when discussing health and
medicine. A patient in need of a central line is in rough shape.
Complications from a botched or infected central line spread rapidly
by the very nature of the procedure and equipment. Oh, right, central lines.
Dr. Pronovost
instituted a checklist for the care and maintenance of central lines.
In the broad scope of modern medicine, it’s a relatively simple
procedure. Go read it. There are 5 steps. Most of which boil down to
“be clean.”
The checklist focused on proper sterilization procedures, and it was
so effective that they had to extend the trial period just to believe
the results. At the end of the experiment, the hospital estimated
that 43 infections and 8 deaths were avoided, to the tune of two
million dollars in savings.
This is the stuff that medicine is all about. Sterile drapes and
thorough hand washing aren’t sexy like a new MRI machine or remote
robotic surgery device, but it saves lives, pain and money.
Despite his initial checklist results, takers were slow to come.
…
There were various reasons. Some physicians were offended by the
suggestion that they needed checklists. Others had legitimate doubts
about Pronovost’s evidence.
(From The Checklist Manifesto)
Doctors and staff can’t be the cause of trouble, especially if
it boils down to cleanliness. They trained to long to make such
simple mistakes.
Damn it.
Pilots get this stuff right. They’re creatures of checklist habit,
and they’re always, always improving those lists and procedures.
Over 12000 B-17 Flying Fortress aircraft were produced, and they
played a major part in Allied operations during World War II. This is
an amazing accomplishment for a plane that many deemed too complex to
fly. Airmen began the process of building and using checklists
because of the B-17, and because of the checklists the B-17 became a
powerful, flyable, weapon of war.
Why can’t doctors behave methodically like pilots? Is it because
pilots put themselves on the line and adherence to methodology is the
only thing that brings them back alive?
And why can’t we, the software developers and sysadmins, get it right?
Our systems lend themselves to checklists. Scratch that, our systems
lend themselves to fully automated checklists in which we should only
need to fix the outliers and amend the list. There is a thrill to being
a code hero that must outweigh the simple joy of consistently shipping
software in a reliable and reportable fashion. At some point that thrill
of riding in to save the day cowboy style loses its charm.
We’re getting better, but we’re still more doctor than pilot in our
ego and methods.
Six groups of four students huddled around their respective lab
tables, waiting for their dissection subject. A cat. A kitty. A
dead, dyed, and preserved Felix catus domestica. Some kids hid their
anxiety behind smiles, others gaped in silence. Cat dissection was the
big deal in Biology II at Bishop Miege High School. Everyone
experienced it, even if they never took the class. Formaldehyde
wafted through the halls, following Bio II students through the rest
of their day.
(The photo is from Flickr. Not my class, or my school, or even my decade…)
I wielded the scalpel about half of the time in my group. I’m not
sure if they were conscientious objectors or just grossed out by the
smell, but two of our four did as little cutting as possible. As the
blade dug through tissue while we traced the route of blood vessels
heading to the kidneys, a thought flashed through my mind: “Holy shit!
We’re hacking the crap out of this cat, and we have the benefit of
dyed blood vessels. Doctors do this to real people? And they live?!”
I never had a strong desire to become a doctor, but that cut crossed
it off my list for good. I liked my science exact, thank you very much.
Little surprise that I ended up slinging bytes for fun and money.
Boolean logic is so orderly, and everything always lines up along
powers of 2 or groups of 8. Unambiguous facts lead us through
problems and root causes as long as we watch closely. Even the
deepest and most difficult problems can be reasoned through with facts
derived from direct observation, although we may retreat from the hunt
with a sigh and a reboot at times.
There’s a downside to all this exactitude for people who play fast and
loose while interacting with tech workers. “All of the processes
restarted” is a verifiable statement, trivially so. Don’t think the
sysadmin won’t check. “Every transaction is failing” will win no
friends within the support ranks once they see that 2 out of 3
transactions are successful. The ISP support line operator knows when
you’ve been bad or good, so reboot your modem for goodness sake.
Facts drive the growth and maintenance of technical projects and
infrastructure. Gather data, analyze it, and act upon it to move
forward. Running on gut feel works only as long as your gut is right.
Scheduled jobs tend to suck a bit. They’re usually written after they’re
needed and dropped into place with little testing and no plans for fixing
them when things go pear-shaped.
This is the third in the series. Here’s the full list that we’ll cover:
If you ever say these words to me as I’m cleaning up a mess caused by
you making a “non-impacting change” to a scheduled job that isn’t
under version control, then you’re going to see a look come across my
face. Behind that look, my brain is calmly keeping my hands from
reaching for the nearest blunt object while mentally filing you away
as “someone who’s lucky to have a job in IT” and trying to figure out
how to best extract ourselves from the mess we’re in. My brain’s
multitasking just isn’t good enough to do those things and maintain a
poker face. Sorry.
This is what happens when you say that version control isn’t necessary.
There are 17 copies of this one script. That’s dumb. This is a fictionalized
real world example, so I’m going to stand up straight and take credit for these
two here:
The sarcasm was lost on this system’s maintainer. Either that, or his
brain’s multitasking managed to keep a straight face while he
pondered the quickest way to punch me in the nuts and get away with it.
Version Control is too Easy
Version control is too easy not to use for the scripts and
configurations that keep your shop humming. You may not trust that
statement if your last encounter with version control involved CVS or,
to a lesser extent, Subversion, but I swear to you that it is true.
Distributed version control systems let you set up repositories on a
local system without ever interacting with a central server. You
don’t need to request a new repository from the version control
gatekeepers, you just need to init a new repository in place. For
bonus points you’re going to back this repository up to a remote
location, but that’s outside of our scope here today.
Right now you just need to pick one of the two following tools:
They both work just about everywhere that matters today, and they behave
nearly identically for the stuff we’ll be doing. If you have developers
on staff or as friends, ask them what they use. Otherwise, flip a coin.
Once you have the binaries installed, you’re only a few commands away
from version controlled bliss. We’ll walk through creating a
repository, seeing the status of the repository, committing unsaved
changes, and reviewing the change log below.
With mercurial:
$ hg init
$ hg status
? really_important_script.sh
$ hg add
adding really_important_script.sh
$ hg commit -m "Committing really_important_script.sh so we don't lose changes like last time."
$ hg log
changeset: 0:0d058a3f5c18
tag: tip
user: Tim Freund <tim@freunds.net>
date: Sat Oct 13 16:09:06 2012 -0500
summary: Committing really_important_script.sh so we don't lose changes like last time.
And with git:
$ git init
Initialized empty Git repository in /Users/tim/src/dvcsdemo/git/.git/
$ git status
# On branch master
#
# Initial commit
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# really_important_script.sh
nothing added to commit but untracked files present (use "git add" to track)
$ git add really_important_script.sh
$ git commit -m "Committing really_important_script.sh so we don't lose changes like last time."
[master (root-commit) 9d9f3d1] Committing really_important_script.sh so we don't lose changes like last time.
0 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 really_important_script.sh
$ git log
commit 9d9f3d12eaa3d56a9bf0e12364c411baafed2753
Author: Tim Freund <tim@freunds.net>
Date: Sat Oct 13 16:10:02 2012 -0500
Committing really_important_script.sh so we don't lose changes like last time.
And that’s really all there is to it. Every time you make a change to
your scripts, simply commit the changes before you move on to your
next task. You’ll eventually want to learn how to revert to previous
versions and share your repositories with others, but just doing what
we’ve worked through today will set you up for success when making
changes to scripts.
Scheduled jobs tend to suck a bit. They’re usually written after they’re
needed and dropped into place with little testing and no plans for fixing
them when things go pear-shaped.
This is the third in the series. Here’s the full list that we’ll cover:
Gah!!! On the surface these crontab files are built to generate a file and transmit
it to a bank, but each of the following made me die a little bit on the inside:
Scripts running out of a developer’s home directory
Magic number parameters (“Tim!”, you yell, “the command
has a help function and it’s up to date. That parameter is obvious
and self documenting!” You’re a dirty liar, and I hate you)
Running one process across multiple hosts without justification when all steps could run on one host
Gross. All of it. We aren’t even here to talk about any of the above,
but you should get in touch if you’d like to know why any of the above
are terrible ideas.
We’re here to talk about trying to orchestrate a complex work flow
with individually scheduled cron jobs. We are not here to talk about
orchestrating a complex work flow with individually scheduled cron
jobs, because that’s not really possible in any realistic way. We are
here to discuss trying (and failing) to do the same.
The road to Hell is paved with good intentions
Our completely fictionalized developer, Victor Richards, means well.
He really wants to be helpful and write things in a way that makes
problem solving easy. Much like breaking up a monster function that
spans pages of editor space into multiple easily composed functions,
he’s broken up the creation and transmission of
ACH files into discrete steps. That’s
legitimately thoughtful. It allows the ops team to retransmit a file
if the bank’s FTP server was down without regenerating it from scratch.
He’s built all the individual components required to make a fairly
robust system that will churn out bank files each business day, but
gluing them together with cron is a recipe for pain and an active
support queue.
Turning up the heat
Victor’s good intentions turn Hellish toward the end of the month.
Website traffic and orders go through the roof. It’s not unusual to
double typical order volume at month end, and quarter and year end
gets even crazier.
That first job in the chain, make_the_ach_file.pl, gets a full 20
minutes to run in the cron schedule. It’s a pretty beastly script
that pulls all of yesterday’s orders out of the database to generate a
bank file, and the queries used aren’t optimized all that well. The
20 minute window usually provides a 5 minute cushion before the next
job, edit_the_ach_file.pl starts to run, at least until the
calendar creeps up to the end of a month. The larger month end order
volume means that the file generation either just barely completes in
time or is late, and the multi-car pile up begins.
Traffic Control
We have three jobs that are tightly related, with each subsequent job
being completely dependent on the job that runs before it. What we
need is some way to ensure that the jobs run serially instead of
achieving accidental parallelism when one of the jobs runs longer than
expected. That turns out to be so easy that you’ll be forgiven for
missing the obvious. It just takes one script:
As a bonus, we still have the individual scripts available for use
during troubleshooting exercises should they be necessary.
This is still the poor man’s form of process orchestration, but we’ve
eliminated an entire class of support issues by ensuring that all the
individual jobs run in the correct sequence, regardless of how long
any of those individual jobs takes to complete.
But wait! There’s more!
This is third in the series.
Subscribe or come back
tomorrow to see more.
Scheduled jobs tend to suck a bit. They’re usually written after they’re
needed and dropped into place with little testing and no plans for fixing
them when things go pear-shaped.
This is the second in the series. Here’s the full list that we’ll cover:
Regardless of the return code or output of that script, you’ll never
see a peep from it. All the output is dumped squarely into the bitbucket.
How do jobs end up configured like this? They’re usually written,
tested, and watched closely for some period of time: a week, a month,
or more. Once the author is convinced that the job is invincible, she
gets tired of seeing the output in her inbox each day, so she adds
the redirection to make things easy for herself.
Only marginally better are the admins that set up an elaborate maze
of mail rules to filter any and all output from scheduled jobs into
some rarely read folder. Sure, the output is there, but it may as
well not be there if it’s getting ignored completely. Yes, it’s
nice to be able to confirm the user error reports that will start
to trickle in, sometimes weeks after the problem started, but it’s
not exactly the professional way to handle things.
I suppose one step beyond that is the admin that rolls into the office
at 10:45, opens Outlook, hits CTRL+A then Delete, and then gets up to
retrieve his morning cup of joe. Cron output problems AND user
problems solved all in one quick key chord. Shameful, but that dude is
so far off the reservation that I’m sure he’s not here among us. Right?
So how do we dodge this?
Find a cron wrapper script that only notifies the team on errors.
Cronic makes this super easy to pull
off. It’s a shell script, so it should run just about anywhere
that matters without compiling anything.
Edit jobs to write their results to a centralized location for
intelligent monitoring and notifications. This has its merits, but
you’re going to need some additional infrastructure and development
time. A big enough shop will justify this. Email can only scale
so far.
Wait for the users to call. They know when the important stuff isn’t
happening. If a job fails in the server room and no one complains,
does it really need to be fixed?
The astute among you will notice that we’re reusing the same list from
our last installment. Two serious suggestions and one suggestion that
is unfortunately in use in far too many places. These two
anti-patterns really are identical twins that were separated at birth. Some
might even combine the two into one, but let’s consider them both
separately lest we over-correct from one straight into the other.
But wait! There’s more!
This is the second in the series.
Subscribe or come back
tomorrow to see more.
Scheduled jobs tend to suck a bit. They’re usually written after they’re
needed and dropped into place with little testing and no plans for fixing
them when things go pear-shaped.
This is the first in the series. Here’s the full list that we’ll cover:
The tricky thing about configuring a scheduled job for the first time
is making sure it actually works. The job is going to run in the dark
recesses of the machine, and you’re going to wonder if it’s really
working at first. Email’s a super easy solution to that problem.
Or the sales and refunds processing jobs didn’t run for three days
last week because a disk was full. Customers are angry, and all of
that bile and vitriol is landing right on top of your boss. These
broken jobs are the most important problem in the world right now on
the second floor of Spacely Sprockets, and the sternly worded
interoffice memo makes that painfully clear through exuberant use of
exclamation points and terrible grammar.
Marching orders in hand, every single scheduled job in the environment
is configured to send an email upon completion or failure.
The only thing that progresses faster than the email notification
configuration is a set of corresponding email rules blazing through
the systems and operations group to filter all of that crap out of
their inboxes.
Oh, look, we’re back to square one! As my manager likes to say: if
everything is important, then nothing is important.
So how do we dodge this?
Find a cron wrapper script that only notifies the team on errors.
Cronic makes this super easy to pull
off. It’s a shell script, so it should run just about anywhere
that matters without compiling anything.
Edit jobs to write their results to a centralized location for
intelligent monitoring and notifications. This has its merits, but
you’re going to need some additional infrastructure and development
time. A big enough shop will justify this. Email can only scale
so far.
Dedicate full time staff to sift through email boxes full of cron
notifications and manually re-trigger jobs. There are people
that actually do this. And if you think it’s a sound solution, then
you’re probably in the wrong job. There’s probably a bank someplace
that would love to hire you as a computer operator.
What if the notification systems break? Or the scheduler just stops?
Oh, they’ll break. Give it time. They’ll break spectacularly.
The big problem with any job monitoring system is watching the
watchmen. Your people or machines have the ability to completely go
off the rails and fail at their jobs for an innumerable number of
reasons. That’s what sent us down this path of notifying on
everything in the first place, remember? People take sick days, and
machines have hard drives that fill up. OK, the hard drives shouldn’t
fill up, but if you’re so smart, then why are you sending emails from
every single one of your scheduled jobs?
Whatever system we use to notify the team of job failures, we also need
to ensure that the scheduled job runner and notifications systems have a
snug and warm place carved out in the NOC’s monitoring system.
Any decent method for sorting the wheat from chaff plus solid monitoring
of the servers that do the grinding should set the course for a sane
scheduled job environment.
But wait! There’s more!
This is just the first in the series.
Subscribe or come back
tomorrow to see more.