We’re about to open registration for OpenStack Upstream
Training,
and we needed to glue together Google Spreadsheets, Trello, and email
to streamline the registration process.
The gspread and
Trello APIs were easy to use, as expected.
I had my doubts about Mailgun, because there was no suggested Mailgun
library. Instead, the docs recommended developers just install
Requests. I expected to
write some boilerplate as a result, but they proved me wrong.
Check out the Mailgun docs for sending an
email.
Examples in 6 languages and curl, and the examples update with your
API endpoints and auth data if you’re logged in. That’s some
Twilio level
documentation, and I’m now a huge fan.
If you want to see how we tie the systems together, check out the
openstack-upstream-registrar
code. I’d like to morph that short script into a small web application
that will guide developers through the ATC process. Reach out if you’d
like to help!
Back on the topic of the training itself: we’re always looking for
more in-class mentors and assistants! If you’ll be in Tokyo on
October 25th and 26th, please consider registering as an
assistant.
I’m thinking about getting in to Ceph development,
and so I’m thinking about how to quickly provision and destroy and
reprovision tiny Ceph clusters at home.
For love of blinking lights, I’ll probably build a cluster with
Banana Pi boards in the future, but for
now I’m just using libvirt and KVM.
Ceph-libvirt-clusterer
lets me clone a template virtual machine and attach as many OSD disks
as I’d like in the process. I’m really happy with the tool
considering that I only have a day’s worth of work in it, and I got to
learn some details of the libvirt API and python bindings in the process.
Building a virtual machine image for one target hypervisor probably
doesn’t cut it anymore. If your organization is like most today, you
run VMware in production, and you’re investigating AWS or OpenStack
for burstability or a full blown migration, and your developers all
run VirtualBox on their laptops. Except for Marvin. Marvin runs KVM
because he’s a contributor to the project.
We can define cross-hypervisor machine definitions with
Packer.
We can run Packer on a variety of machines to provide full hypervisor
coverage with Jenkins.
Packer and Jenkins make a great team. They’re like peanut butter and
chocolate. Or coffee and chocolate. Or pastry and chocolate.
/me grabs a chocolate bar from his drawer and gets back on track.
Many organizations use a single Jenkins server to run continuous
integration builds, but Jenkins supports any number of slave nodes to
distribute load. Further, we can assign labels to those nodes that
define capabilities or other characteristics (host OS, installed
software, special hardware architecture, etc).
Jobs can be pinned to nodes with specific labels, and the NodeLabel
Parameter
Plugin
lets us use node labels as a parameter when building a job.
I give each of my build nodes a label of packer-${builder-name}, then
I can build any machine in my Packer Open Source
Appliances
repository on all of my available local hypervisors and cloud
accounts. My personal list includes qemu, docker, virtualbox-iso, and
openstack (with Rackspace).
I’m pretty excited about this, and I’ll share more details and
possible next steps in a future post. Until then, you can snag
the job definition from my repository.
I mark passages in books while I read, and then I return to the books
later and copy the marked passages into my personal notes.
Among other interesting snippets, I marked and starred four whole
pages in Atul Gawande’s Better. I think that people who highlight
entire pages just don’t quite understand the concept of highlighting,
so my left eyebrow instinctively rose while I attempted to figure out
what the hell I was thinking when I marked such a large passage.
It talks about the difference between 99.5% and 99.95% health rates,
and I’m already very familiar with that difference since they come
up in service level agreements all the time, but this passage doesn’t
recite facts. It tells the story of 99.5% versus 99.95% with a
fantastic narrative that left me with a little lump in my stomach,
and those four pages are enough for me to recommend the whole book,
but you can read that excerpt right now thanks to NPR.
Atul could replace those four pages with a brief exposition of facts:
the difference between being 99.5% and 99.95% successful with a
treatment regimen sums up to a 16% chance or 83% of making it through a year
without complications. Instead he tells a story in four pages that
made me stop, think, and mutter “damn.”
And the impact of a good story isn’t just a momentary pause. Stories
help us retain information. That’s why I thought of Shlemiel the
Painter while full grown adults bickered about string encoding in C
today. Joel Spolsky wrote Back to Basics in 2001, and I still
remember the story of Shlemiel.
Returning to Better before I close out this post, I want to share two
paragraphs from the Afterword (Becoming a Positive Deviant)
Wherever doctors gather - in meeting rooms, in conference halls,
in hospital cafeterias - the natural pull of conversational gravity
is toward the litany of woes all around us.
But resist it. It’s boring, it doesn’t solve anything, and it will
get you down. You don’t have to be sunny about everything. Just be
prepared with something else to discuss: an idea you read about, an
interesting problem you came across — even the weather if that’s all
you’ve got. See if you can keep the conversation going.
My Life in Advertising
is the autobiography of
Claude Hopkins.
It’s out of copyright, so you can also get a legitimate copy from
The Internet Archive.
Everyone reading this post is in sales and marketing, and so everyone
reading this post can gain something from this freely available book.
Three themes repeat throughout the book:
Know your customer, show them value, get the sale.
Trace your advertising efforts through the sale.
Work is play, if framed correctly.
I hosted a
book discussion on The Power of Habit.
If you’ve read that book, Claude’s work on Pepsodent will sound
familiar. Charles Duhigg wrote about Claude’s work on Pepsodent
that helped usher in an age of tooth brushing in America.
Internet marketers pat themselves on the back for A/B testing. Claude
did that in print, and with real, physical product on the line.
Everything old is new again.
What Every Web Developer Should Know About
HTTP
has a long title, but it’s a pretty short read. I didn’t time my
reading, but my Kindle tells me that 30 minutes remain in the book if
I open to the first page.
I bought this book because I’ve considered writing something similar
concerning other topics like DNS or SSL, and I can report that it’s a
decent tour through HTTP.
If you’ve never made a HTTP request by running telnet against a web
server, or never reviewed requests and responses in Wireshark or a
developer console, this book is for you. If you have a junior
developer on the team that’s just learning about web programming, send
them a copy of this to get them started. Examples are in C#, so stay
away if you hate C# and you’re too shallow of a programmer to look
past that choice (and consider yourself judged for that shallowness).
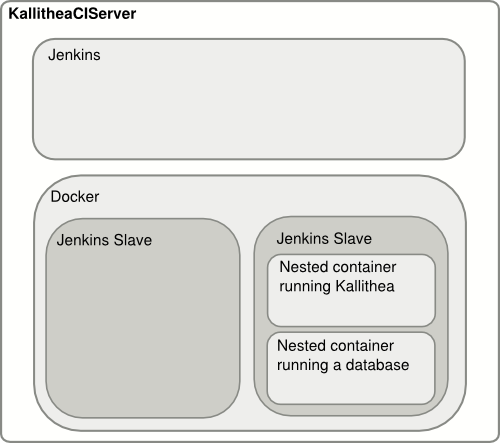
Kallithea is a new source code
management system based on the GPL origins of RhodeCode. The project
needs a continuous integration service running in the open to
sufficiently test incoming patches across a matrix of configuration
variables. I’ve started looking into adding SSH authentication
capabilities, so solid automated testing platform is personally interesting.
I am building a Jenkins server for this purpose. The server build
process is automated with Packer and
Puppet so that we can easily host the
system in a large variety of environments.
We can build rich single use test environments that launch quickly
The system can grow as our testing needs grow
At the least I imagine test jobs to run the following:
Unit tests
Integration tests with various infrastructure components (for instance: sqlite, MySQL, PostgreSQL)
Application upgrade tests
I’m happy to pay for the hosting of the CI service, but the open and
automated deployment definitions will allow anyone to build and run
their own system as well.
The first scraps of configuration are in the following two repositories:
Please let me know if you have any thoughts, questions, or concerns.
In addition to the mailing list, you can find me in the #kallithea IRC
channel as timfreund.
Becoming a Change
Artist
is not bad, but it’s also not in the top three books that I’d
recommend from Gerald Weinberg.
Read it if you have three to four hours to spare, and you’re
interested in the dynamic of change in an organization. Don’t read
it if you’ve heard great things about Mr. Weinberg and want to see
what all the fuss is about.
Start instead with Becoming a Technical
Leader
or The Secrets of
Consulting.
You don’t need to be an official consultant to benefit from The
Secrets of Consulting. Most of consulting involves facilitating
work among groups of humans, and that’s probably a big part of your
job even if you don’t want to admit it.
Remember the agility in the last presentation? Part of that
includes the platform itself: OpenStack releases every 6 months.
No cloud platform is simple: lots of moving parts.
OpenStack runs a sophisticated continuous integration system with Jenkins
eNovance runs a duplicate CI infrastructure chained from the OpenStack CI system.
eNovance also runs a duplicate CI infrastructure chained from their
corporate CI systems in customer cites.
They’ve built tooling to allow progressive upgrades and rollbacks of
installed clouds: rack by rack, for instance.
They often run as little as two weeks behind the stable branch.
As a counterpoint to this, I met with someone who was struggling with
an upgrade for over 6 months. They installed OpenStack’s Diablo
release years ago, and they’ve given up on the idea of smoothly
migrating to Havana (released in November of 2013). Instead, they’re
dropping in a new cloud on new hardware. If you don’t stay up to
date, you’ll get into a treadmill of invasive installations and migrations.
I grabbed one of the last tickets to the OpenStack Upstream
Training
that ran the weekend before the Atlanta OpenStack Summit.
I’ve used open source for longer than I care to remember, and I’ve
even submitted a few patches along the way, but I’ve never become a
member of a project. I felt a little under- and over-qualified
simultaneously. How could I feel overqualified if I had never become
a repeat contributor? I know how to program, but contribution is a
lot more than programming. See if any of the phrases sound familiar:
I just need to sit down and figure it out. (repeated weekly)
I’m going to work on bug $X tomorrow. (repeated weekly)
I hope I do this right, I don’t want to look stupid.
Here’s a hint: “I just need to sit down and figure it out” repeated
more than once is code for “I don’t really want to do this” or “I have
no idea where to start, and I could use a little guidance.” In my
case, it was the latter.
The size and sophistication of OpenStack intimidated me. I’m no
stranger to code review, continuous integration, and automated
testing, but OpenStack is big. There are more hosts running or ready
to run automated tests for OpenStack than we use to service our
biggest application at $DAYJOB. (Check out the “Job Stats” graph on
the Zuul Status Page to see a live
count of hosts.)
My biggest problem was a people problem: I was convinced that while
navigating the OpenStack build and review environment for the first
time I’d make a mistake, and people would think I’m stupid. In
retrospect, that was stupid of me. Of course I’d make mistakes, but
the people and the processes exist to help us build a better product,
accounting for the possibility of mistakes along the way. OpenStack
doesn’t get built in large chunks of caffeine fueled code tossed over
a wall. We build it one small, well reviewed, well tested patch at a time.
The OpenStack Upstream Training broke down into three major components:
The Training Class
The Design Summit
The Mentoring
The Training Class
Scheduled in the two days prior to the Summit, we soaked in the
technical and social processes of OpenStack, and we didn’t have time
forget it all before the Summit began.
The bulk of our classroom training focused on the people and the
social processes in open source, and specifically OpenStack. Behind
every patch and every review comment there is a human being with
hopes, goals, stress, problems, and dreams. We all want to build a
great system, and we’re all constrained to 168 hours each week. The
PTL that doesn’t respond to an email isn’t ignoring you on purpose,
she’s drowning in email and constantly trying to dig out. Gerald
Weinberg reminds us in his writing that “no matter how it looks,
everyone is trying to be helpful.” We can never go wrong with empathy.
Summits are more than just a traditional conference. Design
discussions to shape the next release fill more than half of the week.
Upstream students’ most important assignment for Summit week was to
find and meet the team members that would review our chosen work.
“Introduce yourself, tell them what you’re interested in working on,
and how much time you will commit each week. They are busy, they will
love you.”
I met a large chunk of the Designate team, and I learned how little I
know about running DNS at scale. That’s OK, though, I’ll learn more
as I go, and the team will help along the way.
The Mentoring
The class followed by the summit made for an exhausting week. It
would have been easy to fly home, sleep for a day, and get lost in
$DAYJOB work for a week trying to catch up. “I’ll do some OpenStack
work next week once I’ve caught up on home and work.”
Wrong. The habit of OpenStack contribution isn’t yet built, and
taking a week off will destroy any momentum. The program includes
weekly mentoring sessions to keep students moving forward.
Loic set aside valuable time on Wednesdays and
Saturdays to check in on students and keep them moving toward their
goal, and it was vital for my success. I stayed up until 4:00 AM the
night before my first mentoring session because I didn’t want to let
him down, and I wasn’t happy with my progress thus far.
I now have one patch merged, one under review, and one in work. I’m
also working on improving the automated testing for Designate, and I
suspect I’ll work on documentation in coming months as well.
Should you attend?
You, too, should attend OpenStack Upstream Training if you feel
capable but stuck when considering open source contribution. The
training will give you the social and process knowledge to succeed,
and the encouragement to keep moving forward until you build up your
own momentum. It’s hard work, but it’s fun work.
The Upstream University training changed the trajectory of my career.
I’ll forgive you for dismissing that as hyperbole since I’m still so
early in the process, but I already feel addicted to the scale of
OpenStack and the hum of hundreds of sharp developers and operators
improving it one patch at a time.