We’re about to open registration for OpenStack Upstream
Training,
and we needed to glue together Google Spreadsheets, Trello, and email
to streamline the registration process.
The gspread and
Trello APIs were easy to use, as expected.
I had my doubts about Mailgun, because there was no suggested Mailgun
library. Instead, the docs recommended developers just install
Requests. I expected to
write some boilerplate as a result, but they proved me wrong.
Check out the Mailgun docs for sending an
email.
Examples in 6 languages and curl, and the examples update with your
API endpoints and auth data if you’re logged in. That’s some
Twilio level
documentation, and I’m now a huge fan.
If you want to see how we tie the systems together, check out the
openstack-upstream-registrar
code. I’d like to morph that short script into a small web application
that will guide developers through the ATC process. Reach out if you’d
like to help!
Back on the topic of the training itself: we’re always looking for
more in-class mentors and assistants! If you’ll be in Tokyo on
October 25th and 26th, please consider registering as an
assistant.
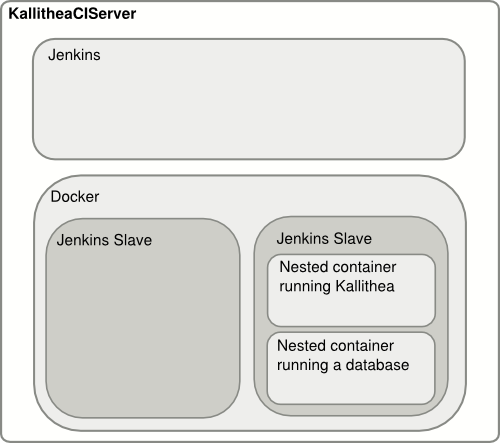
Kallithea is a new source code
management system based on the GPL origins of RhodeCode. The project
needs a continuous integration service running in the open to
sufficiently test incoming patches across a matrix of configuration
variables. I’ve started looking into adding SSH authentication
capabilities, so solid automated testing platform is personally interesting.
I am building a Jenkins server for this purpose. The server build
process is automated with Packer and
Puppet so that we can easily host the
system in a large variety of environments.
We can build rich single use test environments that launch quickly
The system can grow as our testing needs grow
At the least I imagine test jobs to run the following:
Unit tests
Integration tests with various infrastructure components (for instance: sqlite, MySQL, PostgreSQL)
Application upgrade tests
I’m happy to pay for the hosting of the CI service, but the open and
automated deployment definitions will allow anyone to build and run
their own system as well.
The first scraps of configuration are in the following two repositories:
Please let me know if you have any thoughts, questions, or concerns.
In addition to the mailing list, you can find me in the #kallithea IRC
channel as timfreund.
The key to taking great photos is taking a lot of photos. Most of
them will suck, but that’s how it goes.
My photos break down into the following buckets
9165 photos total
424 rated 3+
95 rated 3+ with the tag Dog
3 rated 4+
I want to see the good photos on a regular basis without maintaining a
separate list or directory of the good stuff. I use xscreensaver’s
photopile program, and it likes to read photos from directories.
PhotoFUSE uses
FUSE and
fusepy along
with PIL to expose a
subset of my photo collection as a virtual directory,
filtered by rating and tags.
I’ve already found and fixed a leaky file handles bug, so
you won’t surprise me if you find other issues.
Scenario: You’re running XPath expressions on a document or element
parsed with Python’s ElementTree module, and you can’t find the
expected results. It’s like there are no elements in the tree.
Weirder still, iterating over all elements proves that there are
elements in the tree.
TL;DR: Namespaces. Use them in your queries.
Python’s ElementTree module makes XML processing pretty tolerable,
most of the time. I don’t like digging through XML documents, but I
don’t hate it when I’m using ElementTree and XPath to do the dirty work.
My latest project takes government data provided in Excel spreadsheets
and loads them into a database where I can then serve up the data as
JSON and JavaScript visualizations. The files looked like Excel 2010
spreadsheets on the surface, but they weren’t vanilla. They were
generated with SAS, and uploaded as raw XML documents:
$ file coalpublic1983.xls
coalpublic1983.xls: XML document text
That’s weird for an Excel spreadsheet. Normally they’re zip files with
the XML tucked inside along with various metadata files. Here’s that
same file after opening and saving in LibreOffice:
$ file coalpublic1983.xlsx
coalpublic1983.xlsx: Zip archive data, at least v2.0 to extract
Since they weren’t proper Excel spreadsheets, openpyxl couldn’t read
them. Since they were XML, ElementTree could, but the findall method
returned no elements. A bit of sleuthing showed that the
ElementTree element names included the relevant XML schemas, so rather than
repoze.who.plugins.ldap via repoze.who and pyramid_who
There’s no explicit mention of LDAP support in the pyramid_who
documentation, but a search for “repoze.who ldap” comes up with the
repoze.who.plugins.ldap module.
The last public commit on the repoze.who.plugins.ldap module was
over three years ago on July 22, 2010, and the requirements listed for
the development branch explicitly request versions of repoze.who
greater than or equal to 1.0.6 and less than 2.0dev. The
repoze.who library’s latest release is 2.2, so there’s probably a
bit of work to bring the LDAP plugin into the present.
The other end of the requirements chain is pyramid_who itself.
This is the glue layer that wires repoze.who into Pyramid web
applications, and it was last updated on April 2, 2012. Not quite
abandonware in the same way as the LDAP plugin, but the
last two commit messages are “hail mary” and “endless-piss-me-the-!@#$-off”.
It may still work, but I suspect it won’t be updated as Pyramid
continues to evolve.
pyramid_ldap
Initial investigation looks promising for pyramid_ldap. It’s working
for user authentication against our Unix LDAP directory and our MS
Active Directory instances in the office.
A coworker had some trouble with group retrieval against our Active
Directory, but that wasn’t the library’s fault. Our distinguished
names look something like CN=Freund,
Timothy,OU=Employees,DC=example,DC=com. That comma in our names is
the tricky bit. I don’t see many references to escaping inline commas,
so I suspect we’re in the minority for using CN in our
distinguished names.
If you’re struggling with the same issue, here are two takes on it:
# The double backslash gives us one backslash # once python's internal escaping mechanism runs, # and that single backslash in front of 5C, the # hex code for a backslash, ensures that the # following comma is escaped in the LDAP query. filter='(&(objectCategory=group)(member=CN=Freund\\5C, Timothy,OU=Employees,DC=example,DC=com))'
LDAP authentication in Pyramid is the topic at hand. How does django-auth-ldap
enter into the mix at all? Because the Django folks look like they
have a really nice library for LDAP authentication.
A cursory look at the project shows that the LDAP code is fairly well
abstracted from the Django code. If pyramid_ldap lets you down,
django-auth-ldap may be a great place to find a solution to your problem.
The PassLib New Application Quickstart
Guide
reveals more information about password hashing than I knew at all
before reading the page. Hashing and cryptography are two different
things, but, as with crypto code, it’s best to leave password hashing
to someone who knows the subject front and back.
I spent some time reading through the hashing routine in an old
application to build an administrative password reset tool. We salt,
and we use a decent hashing algorithm, but the code isn’t nearly as
sophisticated as what we’d get with the default context provided by PassLib.
Here’s a preferential order of password storage algorithms:
-2. Passwords stored in plain text -1. Passwords reversibly encrypted 0. Passwords naively hashed with a weak algorithm 1. Passwords salted and hashed 2. Passwords salted and hashed with a carefully chosen algorithm and procedure
Users will reuse passwords in your application. Storing weakly
hashed or encrypted passwords opens your users’ email, social media,
shopping, and banking accounts to fraud and abuse should your
application ever be compromised. Users hate that. Don’t let
your users hate you over something so easy to do well with the
help of open source libraries.
I’ve been working under an assumption: WSGI abstracts away all of the
details of serving up a python web application so well that WSGI web
server implementations are totally interchangeable without thought or worry.
WSGI is awesome, but not quite that awesome. Abstractions are leaky,
it’s a law.
IronBlogger development
has picked back up thanks to Julython, and
the deployment went as planned until I restarted the process. It got
stuck in an infinite loop of restarting itself, with exceptions thrown
in the database initialization code.
I used the pip freeze command to dump lists of installed software in
each host, and gunicorn was the only additional bit of code in the
production environment. And, sensibly, the only difference outside of
turning off live debugging was the gunicorn configuration:
I haven’t figured out exactly what the problem is, but I’m getting close. This
is primarily a public service announcement: test your code with the same server
software that it’ll run on in production. Abstractions are leaky, and it
may work for a while, but one day it won’t.
Python, SQLAlchemy and “ORA-01461: can bind a LONG value only for insert into a LONG column”
If you’re on this page you either read all of my entries regardless of
content (thank you!) or you have the error above.
Look through just about every ORM and you’ll find special case
handling for Oracle’s large objects. If there’s no special case
handling in the ORM itself, then you will write some special case code yourself.
SQLAlchemy’s special case handling of Oracle’s large objects is to
automatically load the large objects when retrieving rows from the
database and convert them to strings. This means the database results
object isn’t tethered to the database cursor while you work. It’s
pretty handy, and if you’re just pulling data from the database it
means you may never need to think about how weird Oracle large objects
are compared to “regular” data.
I was reading and writing large objects between two schemas when the
ORA-014161 surfaced. Since this was a one-time ad-hoc deal, I just
hand crafted some SQL, and the script looked a little like this:
sql="insert into the_interesting_table(%s) values(:%s)"%(names,value) targetdb.execute(sql,**params)
Python
And that failed terribly with the following:
"ORA-01461: can bind a LONG value only for insert into a LONG column"
Of course it did, otherwise we wouldn’t be here now. Since the
values came out of the source database and were converted to strings,
SQLAlchemy then attempted to drop them into the target database as strings.
SQLAlchemy is smart enough to coerce types correctly if we give it
some information about our schema, either explicitly or by asking it
to autoload table metadata. A few changes to the script above and we
were in business without manually hacking together SQL:
About the same number of lines, but less hacky and it actually works
by letting SQLAlchemy do more heavy lifting for us. Since SQLAlchemy
has metadata information for the target table, it knows that any input
for the large object columns will need to be properly converted.
Any tool that successfully abstracts away Oracle large objects is a
good tool in my book.
Giles Bowkett emphasizes the importance of picking tools that have
export formats in his
Time
Management for Alpha Geeks video. I can’t agree more. Web
connected make my data available most everywhere I go, but I get
nervous when I can’t back up with a local copy. Web services come,
and web services go.
I have used Don’t Break The Chain for 9 months. It
tracks 9 different habits for me, and I hope it continues to run for
a very long time. To ensure that I will never lose my data regardless
of DBTC’s continued operation, I wrote an export script. It logs in
to the service and outputs chain data as a CSV. It will optionally
export to JSON as well.
I pushed a new project up to github. It is
called svgcsvimg,
and it generates a series of PNG images from an SVG template and data
provided in a CSV file.
I built this tool because I was too lazy to manually create intro
slides for a series of videos. I made the slide template, put all
of the video metadata into a csv file, and then spent two hours hacking
out this little project. It’s true: I could have manually created
all of those slides in that time, but then I wouldn’t have this code
to give away.
My general rule of thumb is to do something manually once. If it comes
up a second time, I will manually complete the task and write down the
steps with an eye toward repeatable automation. Then I’m ready to write
up code when that third time comes around. I had twenty slides to produce,
so I jumped straight to step three for this project.
I used Inkscape to create the template,
and the SVG rendering was done with a combination of Pycairo and RSVG.
Using Jokosher? Are you getting the error message “You do not have
any LADSPA effects plugins installed” when attempting to add effects
to an instrument?
Do this:
rm -rf ~/.gstreamer-0.10/registry*
If you want more information, you can find
it in
the GStreamer FAQ. The bug is now closed, but this is still an
issue in Ubuntu 10.04. Once Ubuntu updates their GStreamer packages
this post should be obsolete.
I drove to Waco, TX for PyTexas 2010 this weekend. It was
fantastic, and that’s even accounting for the 20 hours I spent behind
the wheel. We had a great turn out, and a lot of good talks.
A huge “thank you” to Bill Chipman and Josh Marshall for
volunteering their time, talents, and gear to the recording effort.
In typical fashion I figured I’d lug a bunch of gear down I-35 and
things would just work out, but it wouldn’t have gone nearly as well
if I had to tackle three rooms all by myself.
A hard drive with the raw files will ship to Bill later this week, and I
think we can get them ready for upload within the next week or two.
Stay tuned for more updates!
I’ve spent a few hours over the last week working on a Python DNS
server that uses a database to store name records. Reactions to this
probably come in one of two flavors: “Cool!” or “Seriously, WTF, use
an existing solution!”
Either a proper dynamic DNS server or at least a DNS server with
some form of API will do. I work on some sysadmin software and other
software that makes use of network services.
I never have fully grasped Twisted’s deferred model
Sure, I’ve written some code that uses Twisted, but it is ugly,
and it never feels quite right or natural to me. I’d like to really
wrap my head around that style of code.
The NomenPy
project is my attempt to satisfy both of those needs. Twisted
comes with a fully baked DNS implementation. This allows me to build
out a programmable database backed DNS server as a thin veneer over
a Twisted foundation. I can see real results while working on a real
problem and learning a new style of programming.
With all of that said, understand that I’m a complete noob
when writing code to fit Twisted’s model. If the code is an atrocious
misuse of Twisted, please let me know what I did wrong. Much thanks
in advance!
 Giles Bowkett emphasizes the importance of picking tools that have
export formats in his
Giles Bowkett emphasizes the importance of picking tools that have
export formats in his